
Цветанка Николова. Честотен речник на българската разговорна реч
Предназначение: Цветанка Николова. Честотен речник на българската разговорна реч. Наука и изкуство. София. 1987. Речникът е представен като текстов файл, което много облекчава извличането на глотометрични характеристики. По-долу давам пример.
ИЗТЕГЛЯНЕ: cvetanka_nikolova_rechnik.zip (MD5 7b4baeef0fce3b7d32694ee689fae502).
Архивът съдържа следните текстови файлове (кодиране UTF-8):
cvetanka_nikolova_rechnik_utf8.txt — Речникът като текстов файл. По-долу ще обяснявам структурата на речниковата статия.
cvetanka_nikolova_grammar.txt — честотен речник на граматическите бележки от речника (в текста те са в квадратни скоби).
cvetanka_nikolova_semantics.txt — списък на „семантичните“ бележки (в текста те са в кръгли скоби).
Заглавката на речниковата статия започва на пълен ред. Тя задължително съдържа основната форма на думата. След нея с шпация може да следва граматическа характеристика (винаги в квадратни скоби). След нея с шпация може да следва някакво семантично указание (винаги в кръгли скоби). Разделител между тази текстова част и следващата (количествената част) е табулатор. След табулатора има две цели числа, разделени с наклонена черта (slash) — първото е общата сума на всички лекси на тази лексема в текста, второто е броят на извадките, в които се срещат лекси на тази лексема.
Защото речникът е съставен от 5 извадки по 20 килолекси и точно тази негова структура го прави много полезен за глотометриста. По-долу ще дам пример как се работи с този текстов файл, а и другаде ще давам примери с него. Щото наистина е много полезен.
След заглавката са изброени всички лекси, с които се е срещнала лексемата в текста. Всяка лекса е изведена на отделен ред след табулатор. След лексата може да има в квадратни скоби граматическа характеристика и (само в три случая) в кръгли скоби семантично указание. Отново след текстовата част с табулатор са отделени количествените данни — те представляват пет цели числа (честотите на лексатат във всяка от петте извадки) и са разделени с шпация.
Ето примери (символът за табулатор е отбелязан в синичко):
викам [гл.] (крещя)<TAB>3/2 <TAB>вика<TAB>0 1 0 0 1 <TAB>викахме<TAB>0 0 0 0 1 да [част.] (за потв.)<TAB>691/5 <TAB>да<TAB>86 171 99 149 186 да [част.]<TAB>3249/5 <TAB>да (в съюз)<TAB>30 14 26 20 11 <TAB>да (+гл.)<TAB>712 610 710 518 598
И ето как би изглеждало това горе-долу в редактора ви:
викам [гл.] (крещя) 3/2 вика 0 1 0 0 1 викахме 0 0 0 0 1 да [част.] (за потв.) 691/5 да 86 171 99 149 186 да [част.] 3249/5 да (в съюз) 30 14 26 20 11 да (+гл.) 712 610 710 518 598
* * *
А сега да помислим върху частицата да — често срещана в български текстове, с разнообразни функции, очевидно „граматикализирана“ (аз бих предпочел да използвам термина на Янакиев — сихноморфема, тоест морфема с висока честота), а май нямаме повече количествени данни върху нея, от предоставените тук от Цв. Николова. Можем ли да извлечем още малко информация от тези данни?
Можем. И възможност за това ни дават числовите редове от по пет числа (честотата на явлението във всяка от петте 20-килолексни извадки, от които е формиран речникът).
Да погледнем сумите за потвърдителната частица да (691) и за приглаголното да (3249). Те не ни говорят кой знае колко много. Вярно, приглаголното да е близо пет пъти повече, ама какво от това? Има ли някаква гаранция, че ако направим друга 100 килолексна извадка от разговорни български текстове, няма да се случи така, че потвърждаващата частица да да е повече от приглаголната?
Числовите редове, включени в речника на Цветанка Николова, ни дават възможност да приложим добре разработени математикостатистически методи и да получим смислен отговор на този въпрос.
Обърнете внимание на думата „математикостатистически“ — за да са убедителни изводите ни, те трябва да са съобразени строго с изискванията на математическата статистика.
Ама това не сме го учили в училище!? Е, да — ще се наложи да се самообразоваме.
Картинката по-долу показва как в графичната конзола на IPython се извършват нужните пресмятания. В редовете, започващи със синичко In, аз пиша команди; в редовете, започващи с червеничко Out интерпретаторът ми „отговаря“, тоест, изнася резултата от изпълнението на съответната команда. На ред 10 съм сбъркал изписването на mean и интерпретаторът „пищи“, ама дава обяснения къде съм сбъркал, нали. Това може да се случи на всеки — погледнете го и си поправете грешката.
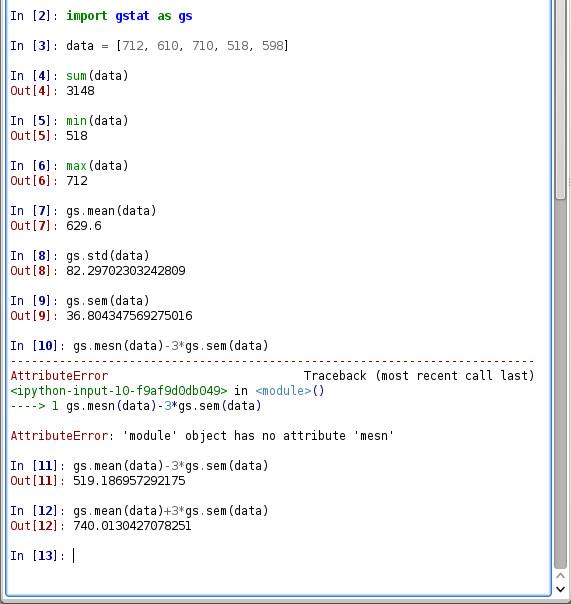
На ред 2 аз въвеждам библиотеката/модула gstat (от glotta), ама й съкращавам името до gs, за да пиша по-малко.
На ред 3 създавам памет data и записвам в нея данните от приглаголното да. Не съм ги писал тези числа, копирал съм ги от редактора, ама съм ги затворил в квадратни скоби и съм наслагал запетаи, защото така иска пайтън; иначе ще даде грешка.
Функциите sum(), min() и max() са си „вградени“ в пайтън и дават съответно сумата на числата в числовия ред, най-малкото и най-голямото число. Разликата между най-голямото и най-малкото число показва размаха на данните в извадката — това е първична и най-груба оценка за разсейването на числата в числовия ред.
Всички тези данни вие си ги записвайте било на листче, било в редактора.
По-надолу използвам функциите от gstat.
Функцията gs.mean() изчислява средната аритметична величина. Вие си я запишете така: 629.60 — по този начин (с „излишната“ нула) показвате на грамотните количествено хора, че представяте резултатите от пресмятанията с две цифри след десетичната точка/запетая. По-нататък и останалите резултати ще ги закръгляме до една стотна. В глотометрията такава точност на представяне на резултатите е обикновено напълно достатъчна. А интерпретаторът на пайтън нека извършва изчисленията с каквато си може точност.
Функцията gs.std() е съкращение от англ. standard deviation, средно квадратично отклонение или понякога стандартно отклонение на български. Това е сериозно мотивирана оценка за „разсейването“ на данните, много по-сериозно мотивирана от размаха, например. Това се обяснява във всеки учебник по математическа статистика, а у Янакиев (в „Стилистиката и езиковото обучение“) това е и „човешки“ обяснено много добре. Резултатът си го запишете така: 82.30.
Изненадвате ли се? Припомнете си правилата за закръгляване на числа.
Функцията gs.sem() е съкращение от англ. standard error of mean, тоест стандартна грешка на средната аритметична и дава възможност да пресметнем в какъв интервал би трябвало да се намира средната аритметична на приглаголното да във „всички“ български разговорни текстове. Статистиците биха казали „в генералната съвкупност“. Логиката, по която се извежда тази оценка в математическата статистика, е много забавна, ама нека да го оставим за друг разказ…
Ако утроите тази оценка и я извадите и прибавите към средната аритметична (това е вариант на правилото за „трите сигми“; със σ, не винаги съвсем правилно, означават средното квадратично отклонение), ще получите оценка за интервал, в който би трябвало да влиза средната аритметична на приглаголното да с вероятност 99.7%. Тези две числа съм пресметнал на 11 и на 12 ред. Не се чудете сега откъде измислих тези 99.7% — това се обяснява в учебниците по математическа статистика, не е сложно, ще го разберете.
Казано по-разказвателно (но и малко неточно): математическата статистика допуска, че ако направите хиляда речника на разговорната реч, като този на Цв. Николова, няма да е изненада, ако в около три от тях средната аритметична на приглаголното да е извън интервала 519.19–740.01.
Опитайте, моля, да направите в IPython същите изчисления за потвърждаващото да: [86, 171, 99, 149, 186]. Би трябвало да получите следните резултати:
| приглаголно да | потвърждаващо да | |
| N | 5 | 5 |
| sum | 3148 | 691 |
| min | 518 | 86 |
| max | 712 | 185 |
| mean | 629.60 | 138.20 |
| std | 82.30 | 43.99 |
| sem | 36.80 | 19.67 |
| mean(min) | 519.19 | 79.19 |
| mean(max) | 740.01 | 197.21 |
Потвърждаващото да никак не изглеждат малко; сумата е 691, а средната аритметична 138.20 също не изглежда ниска. Ама оценката за разсейването (средното квадратично отклонение) също не е никак малка: 43.99. Та си струва да направим проверка по „правилото на трите сигми“ — умножете по три средното квадратично отклонение и извадете резултата от средната аритметична (трябва ли да подсказвам? това се пресмята в IPython):
138.20 - 3 * 43.99 = 6.24
За щастие резултатът е положителен. Ако бяхме получили като резултат отрицателно число, това щеше да означава, че данните не са ни достатъчни. Както виждате, тази проверка не зависи от количеството данни, които обработваме, а най-вече от стойността на средното квадратично отклонение. Така че е желателно да правите тази проверка, преди да преминете към по-нататъшни изводи.
В глотометрията, ако данните се окажат недостатъчни, най-простото решение обикновено е да прибавим още малко данни. И само за сведение: в случай, че е невъзможно да намерите повече данни, математическата статистика пак ще ви помогне — има разработени методики за работа с такъв тип данни, ама те изискват повече знания и повече пресмятания.
При известен опит с количествена обработка на данни може да се прецени „на око“ по двата последни реда на таблицата, че вероятността да се приближат средните аритметични на двете употреби на да е нищожна — двата интервала, в които очакваме да варират средните аритметични с почти 100-процентова сигурност, не само не се застъпват, но дори са доста отдалечени един от друг: 519.19 – 197.21 = 321.98. Разликата е по-голяма от ширината на всеки един от интервалите. Ама това наблюдение все още не е „облечено“ в математикостатистическа форма, не сме му придали стохастическа (вероятностна) форма.
В математическата статистика са разработени методи за стохастическа (вероятностна) оценака на разликата между двете средни аритметични. В глотометрическата практика добре се представя (свободно цитирам Янакиев) t-критерият на Стюдънт. Но…
Но t-критерият на Стюдент е параметричен. Това ще рече, че данните трябва да се вписват достатъчно добре в модела на Гаусовото (нормалното) разпределение, за да можем да приложим критерия.
В модула scipy има подмодул stats — голяма статистическа библиотека, — а към него има метод normaltest(). Той извършва даже два различни статистически теста дали данните ни се вписват добре в Гаусовото разпределение. Да опитаме да го използваме.

Няма да стане! Съобщението е съвсем ясно — данните ни са малко. А вие какво очаквате от числов ред с пет числа? Това е много по-добре от простите суми — вече показах ползата от това, — ама чудеса все пак не можем да очакваме.
Затова ще направим един по-семпъл тест — ще пресметнем коефициента на вариация и ако той е под 33% за двата числови реда, ще приемем, че можем да използваме t-критерия на Стюдънт.

Резултатът от работата на метода gstat.cvar() е в проценти, тоест 31.83% и 13.07%. Коефициентът на вариация за първият числов ред (данните за потвърждаващото да) е доста висок, но все пак е под 33%, та пресмятаме и t-критерия на Стюдънт.
Изчислената стойност на t-критерият е висока: 11.78 срещу 5.04 критична стойност при равнище на значимост 0.001 (тия данни може да ги вземете от таблиците към учебниците по статистика или с малко повече опит да ги пресметнете чрез статистическия модул scipy.stats).
И ето едно от предимствата на съвременните компютри — ние получаваме и равнището на значимост (α) за изчислената стойност на критерия 11.78. Това е много малко число: 0.0000025.
Ние тръгнахме от песимистичното допускане, че в следващият речник, направен като този на Цв. Николова, може честотата на потвърждаващото да да е по-голяма от честотата на приглаголното да.
Сега можем да кажем на песимиста така: нашите пресмятания показаха, че ако направим един милион речника на разговорната реч като този на Цв. Николова, в два или три от тях е възможно средните аритметични на двете да-та да са толкова близки, че t-критерият на Стюдънт да показва разликата между тях като случайна.
Много моля! Пак прочетете предишното твърдение.
Изводите от статистическите обработки често изглеждат такива, „сложни“ и „описателни“.
Ние не твърдим, че потвърждаващото да ще стане по-голямо от приглаголното да, а твърдим само, че в два или три случая на милион средната атитметична на потвърждаващото да ще се приближи толкова до средната аритметична на приглаголното да, че t-критерият на Стюдънт да не оценява разликата като значима.
Очевидно е, че вероятността средната аритметична на потвърждаващото да да стане по-голяма от средната аритметична на приглаголното да е още по-малка.
Сигурно забелязахте, че в пресмятанията изобщо не включих употребата на да в сложни съюзи от типа за да, само да, макар да, а това е очевидно приглаголна употреба. Опитайте да ги включите и тях и вижте какво ще се получи. Резултатът може да ви насочи към полезни размисли.
В този пример аз показах предимно техники, с които може да използвате данните от речника. Филологическата част не беше чак толкова съществена — надали някой филолог българист ще допусне, че потвърждаващото да в български текстове може да е повече от приглаголното да.
По-нататък ще дам и по-полезни резултати. Ама се надявам, че се убедихте колко повече информация ни дават числовите редове (дори само от по пет числа) в сравнение със сумарните честоти, каквито предоставят повечето честотни речници.
* * *
А задавате ли си въпроса защо извадките, от които е създаден речникът, са по 20 килолекси? А не по 45 килолекси, например, както е изграден Британският национален корпус?
Когато през 60-те години Мирослав Янакиев започва изграждането на глотометричния архив към катедрата Български език на Софийския университет, той установява, че обработката на текст от 20 килолекси е по силите на един дипломант, като едновременно с това е достатъчен, за да се видят основните характеристики на текста. Та този обем на текста се е превърнал в нещо като практически стандарт у нас.